
The Great Simplification Experiment
📙 This is the last in a multi-part series on creating web applications with generative AI integration. Part 1 focused on discussing the AI stack and why the application layer is the best place in the stack to be. Check it out here. Part 2 focused on why Ruby is the best web language for building AI MVPs. Check it out here. I highly recommend you read through both parts before reading this article to get caught up on terminology used here.
Table of Contents
- Introduction
- Level 1: As Complex As It Gets
- Level 2: Drop the Cloud
- Level 3: Microservices Begone!
- Level 4: SQLite Enters the Chat
- Summary
Introduction
In this article, we will be conducting a fun thought experiment. We seek to answer the question:
How simple can we make a web application with AI integration?
My readers will know that I value simplicity very highly. Simple web apps are easier to understand, faster to build, and more maintainable. Of course, as the app scales, complexity arises out of necessity. But you always want to start simple.
We will take a typical case study for a web application with AI integration (RAG), and look at four different implementations. We are going to begin with the most complex setup that is composed of the most popular tools, and attempt to simplify it step-by-step, until we end up with the most simple setup possible.
Why are we doing this?
I want to inspire developers to think more simply. Oftentimes, the “mainstream” route to building web apps or integrating AI is far too complex for the use case. Developers take inspiration from companies like Google or Apple, without acknowledging that tools that work for them are oftentimes inappropriate for clients working at a much smaller scale.
Grab a coffee or tea, and let’s dive in.
Level 1: As Complex As It Gets
Suppose a client has asked you to build a RAG application for them. This application will have one page where users can upload their documents and another page where they can chat with their documents using RAG. Going with the most popular web stack currently in use, you decide to go with the MERN stack (MongoDB, Express.js, React, and Node.js) to build your application.
To build the RAG pipelines that will be handling document parsing, chunking, embedding, retrieval, and more, you again decide to go with the most popular stack: LangChain deployed via FastAPI. The web app will make API calls to the endpoints defined in FastAPI. There will need to be at least two endpoints: one for calling the indexing pipeline and another for calling the query pipeline. In practice, you will also need upsert and delete endpoints, to ensure that the data in your database stays in sync with the embeddings in your vector store.
Note that you will be using JavaScript for the web application, and Python for the AI integration. This duo-lingual app means you will likely be using a microservices architecture (see part 2 of this series for more on this). This is not a strict requirement, but is often encouraged in a setup like this.
There is one more choice to be made: what vector database will you be using? The vector database is the place where you store the document chunks created by the indexing pipeline. Let’s again go with the most popular choice out there: Pinecone. This is a managed cloud vector database that many AI developers are currently using.
The whole system might look something like the following:
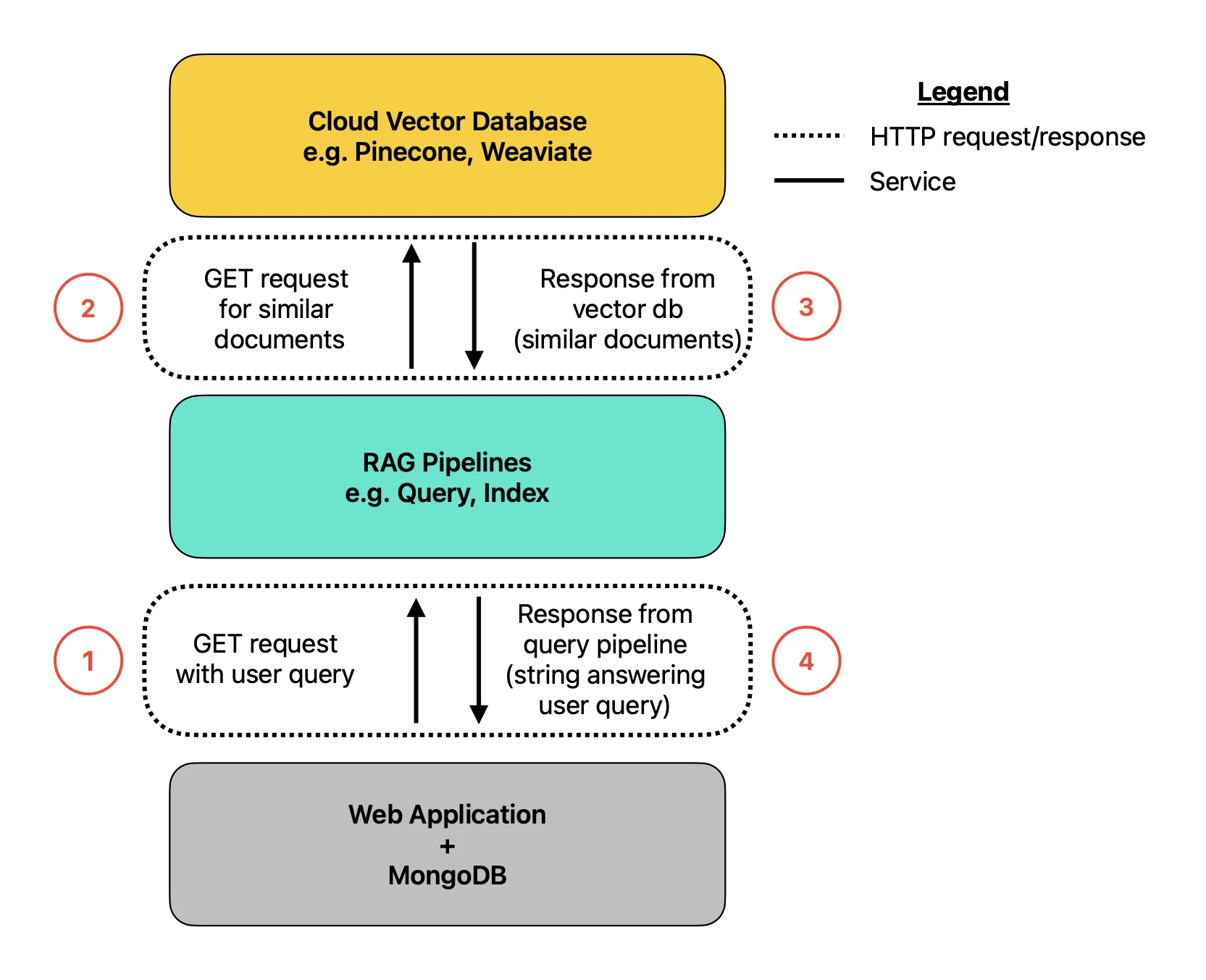
A traditional RAG application. Image by author.
Yikes! There are a lot of moving pieces here. Let’s break things down:
-
At the bottom rectangle, we have the web application and MongoDB backend. In the middle we have the RAG pipelines built with LangChain and FastAPI. At the top, we have the Pinecone vector database. Each rectangle here represents a different service with their own separate deployments. While the Pinecone cloud vector database will be managed, the rest is on you.
-
I have wrapped example HTTP requests and corresponding responses with a dotted border. Remember, this is a microservices architecture, so this means HTTP requests will be needed anytime inter-service communication occurs. For simplicity, I have only illustrated what the query pipeline calls would look like and I have omitted any calls to OpenAI, Anthropic, etc. For clarity, I numbered the requests/responses in the order in which they would occur in a query scenario.
-
To illustrate one pain point, ensuring the documents in your MongoDB database are synced with their corresponding embeddings in the Pinecone index is doable but can be tricky. It takes multiple HTTP requests to go from your MongoDB database to the cloud vector database. This is a point of complexity and overhead for the developer.
A simple analogy: this is like trying to keep your physical bookshelf synced up with a digital book catalog. Any time you get a new book or donate a book from your shelf (turns out you only like the Game of Thrones show, not the book), you have to go and manually update the catalog to reflect the change. In this world of books a small discrepancy won’t really impact you, but in the world of web applications this can be a big problem.
Level 2: Drop the Cloud
Can we make this architecture any simpler? Perhaps you read an article recently that discussed how Postgres has an extension called pgvector. This means you can forgo Pinecone and just use Postgres as your vector database. Ideally you can migrate your data over from MongoDB so that you stay with only one database. Great! You refactor your application to now look like the following:
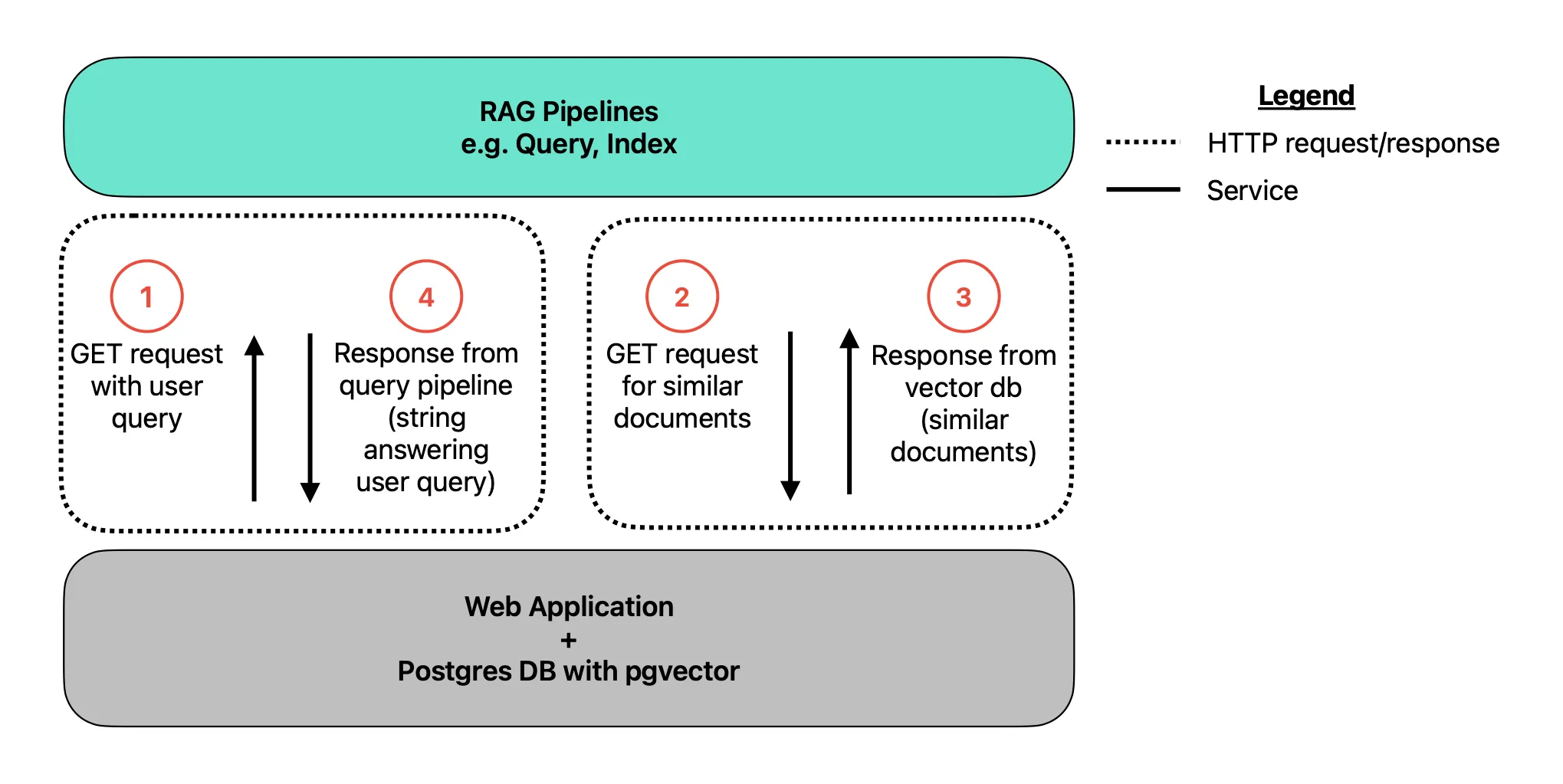
A simplified RAG application. Image by author.
Now we only have two services to worry about: the web application + database and the RAG pipelines. Once again, any calls to model providers has been omitted.
What have we gained with this simplification? Now, your embeddings and the associated documents or chunks can live in the same table in the same database. As an example, you can add an embeddings column to a table in PostgreSQL by doing:
ALTER TABLE documents
ADD COLUMN embedding vector(1536);Maintaining coherence between the documents and embeddings should be much simpler now. Postgres’ ON INSERT/UPDATE triggers let you compute embeddings in-place, eliminating the two-phase “write doc/then embed” dance entirely.
Returning to the bookshelf analogy, this is like ditching the digital catalog and instead just attaching a label directly to every book. Now, when you move around a book or toss one, there is no need to update a separate system, since the labels go wherever the books go.
Level 3: Microservices Begone!
You’ve done a good job simplifying things. However, you think you can do even better. Perhaps you can create a monolithic app, instead of using the microservices architecture. A monolith just means that your application and your RAG pipelines are developed and deployed together. An issue arises, however. You coded up the web app in JavaScript using the MERN stack. But the RAG pipelines were built using Python and LangChain deployed via FastAPI. Perhaps you can try to squeeze these into a single container, using something like Supervisor to oversee the Python and JavaScript processes, but it is not a natural fit for polyglot stacks.
So what you decide to do is to ditch React/Node and instead use Django, a Python web framework to develop your app. Now, your RAG pipeline code can just live in a utility module in your Django app. This means no more HTTP requests are being made, which removes complexity and latency. Any time you want to run your query or indexing pipelines all you have to do is make a function call. Spinning up dev environments and deployments is now a breeze. Of course, if you read part 2, our preference is not to use an all Python stack, but instead go with an all Ruby stack.
You’ve simplified even further, and now have the following architecture:
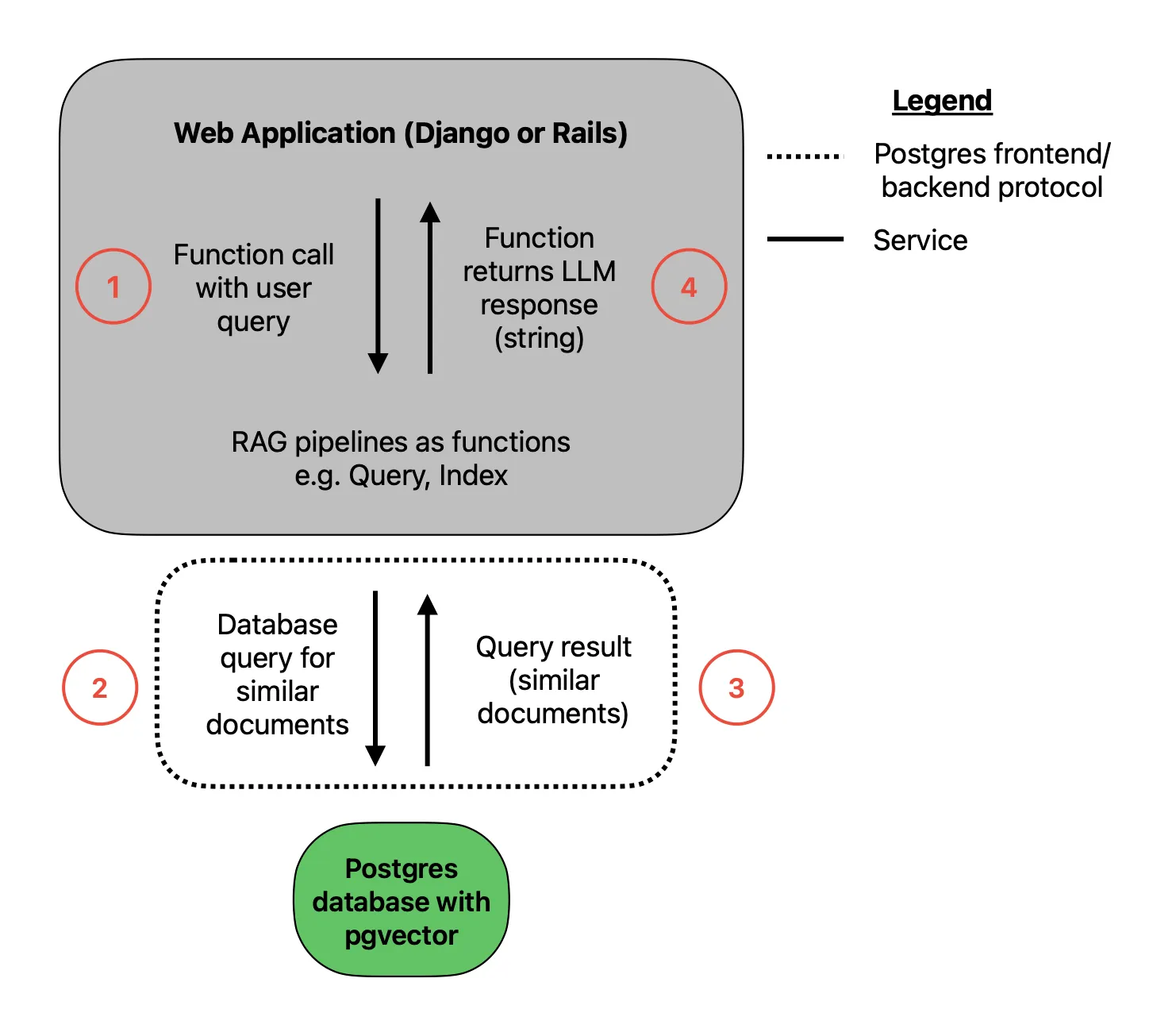
An even simpler RAG architecture. Image by author.
An important note: in earlier diagrams, I combined the web application and database into a single service, for simplicity. At this point I think it’s important to show that they are, in fact, separate services themselves! This does not mean you are still using a microservices architecture. As long as the two services are developed and deployed altogether, this is still a monolith.
Wow! Now you only have a single deployment to spin up and maintain. You can have your database set up as an accessory to your web application. This unfortunately means you will still likely want to use Docker Compose to develop and deploy your database and web application services together. But with the pipelines now just operating as functions instead of a separate service, you can now ditch FastAPI! You will no longer need to maintain these endpoints; just use function calls.
A bit of technical detail: in this chart, the legend indicates that the dotted line is not HTTP, but instead a Postgres frontend/backend protocol. These are two different protocols at the application layer of the internet protocol model. This is a different application layer than the one I discussed in part 1. Using an HTTP connection to transfer data between the application and the database is theoretically possible, but not optimal. Instead the creators of Postgres created their own protocol that is lean and tightly coupled to the needs of the database.
Level 4: SQLite Enters the Chat
“Surely we are done simplifying?”, you may be asking yourself.
Wrong!
There is one more simplification we can make. Instead of using Postgres, we can use SQLite! You see, currently your app and your database are two separate services deployed together. But what if they weren’t two different services, but instead your database was just a file that lives in your application? This is what SQLite can give you. With the recently released sqlite-vec library, it can even handle RAG, just like how pgvector works for Postgres. The caveat here is that sqlite-vec is pre-v1, but this is still great for an early stage MVP.
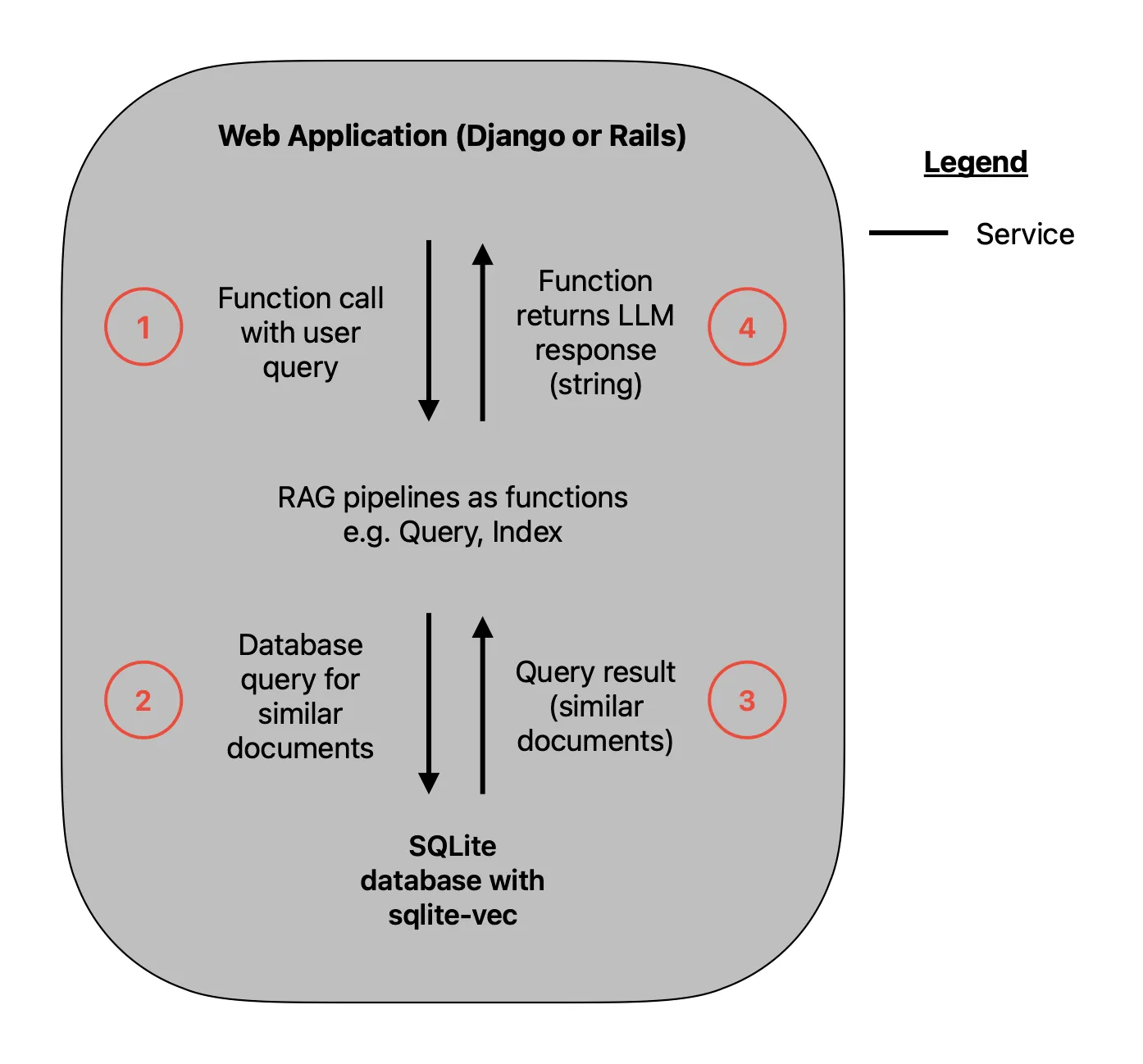
The simplest possible architecture. Image by author.
Truly amazing. You can now ditch Docker Compose! This is truly a single service web application. The LangChain modules and your database now all are just functions and files living in your repository.
Concerned about the use of SQLite in a production web application? I wrote recently about how SQLite, once considered just a plaything in the world of web apps, can become production-ready through some tweaks in its configuration. In fact Ruby on Rails 8 recently made these adaptations default and is now pushing SQLite as a default database for new applications. Of course as the app scales, you will likely need to migrate to Postgres or some other database, but remember the mantra I mentioned in the beginning: only introduce complexity when absolutely necessary. Don’t assume your app is going to blow up with millions of concurrent writes when you are just trying to get your first few users.
Summary
In this article, we started with the traditional stacks for building a web application with AI integration. We saw the amount of complexity involved, and decided to simplify piece by piece until we ended up with the Platonic ideal of simple apps.
But don’t let the simplicity fool you; the app is still a beast. In fact, because of the simplicity, it can run much faster than the traditional app. If you are noticing that the app is starting to slow down, I would try sizing up the server before considering migrating to a new database or breaking up the monolith.
With such a lean application, you can truly move fast. Local development is a dream, and adding new capabilities can be done at lightning speed. You can still get backups of your SQLite database using something like Litestream. Once your app is showing real signs of strain, then move up the levels of complexity. But I advise against starting a new application at level 1.
I hope you have enjoyed this series on building web applications with AI integration. And I hope I have inspired you to think simple, not complicated!